
※本記事は広告を含みます。
メモリ領域解説シリーズ
本記事は「メモリ領域解説」シリーズの1つです。
C言語のプログラムでは、メモリは複数の領域に分かれて管理されています。
例えば次のような領域があります。
- text領域:プログラムのコード
- data領域:初期値ありのグローバル変数
- bss領域:初期値なしのグローバル変数
- heap領域:mallocで使用する動的メモリ
- stack領域:関数呼び出しで使用するメモリ
この中でも **プログラムの実行に強く関わるのが「スタック領域」**です。
この記事では
- スタック領域の役割
- スタックの仕組み
- ヒープとの違い
を 実務の視点も交えて解説します。
スタック領域とは
 新人さん
新人さんスタック領域って、メモリ構造の図ではよく見るんですが…
実際には何を保存しているんですか?
 エンジニアくん
エンジニアくん主に関数の実行に必要な情報を保存しているんだ。
ローカル変数や戻りアドレスなどがスタックに積まれるよ。
**スタック領域(Stack)**とは、
関数呼び出し時に使用されるメモリ領域です。
主に次の情報が保存されます。
- ローカル変数
- 関数の引数
- 戻りアドレス
- 保存されたレジスタ
関数が呼び出されると、
これらの情報が スタックに積まれる(push) 仕組みになっています。
そして関数が終了すると、
そのデータは スタックから取り出され(pop)、メモリが解放されます。
スタックの特徴
スタック領域には次の特徴があります。
LIFO構造(後入れ先出し)
スタックは LIFO(Last In First Out) の構造を持っています。
つまり
- 最後に積まれたデータ
- 最初に取り出される
という仕組みです。
例えば次のような関数呼び出しがあるとします。
main()
└ funcA()
└ funcB()この場合、スタックには次の順でデータが積まれます。
funcB
funcA
mainそして関数終了時は 逆順で戻ります。
自動管理される
スタックのメモリは プログラムが自動で管理します。
つまり
- malloc
- free
のような 手動メモリ管理は不要です。
関数が終了すると、そのスタックフレームは自動的に解放されます。
このため、スタックは 高速にメモリ管理できるという特徴があります。
スタックとヒープの違い
初心者さんスタックとヒープって、どっちもメモリですよね?
何が違うんですか?
エンジニアくん一番大きい違いは、メモリ管理の方法だね。
スタックとヒープの主な違いは次の通りです。
| 項目 | スタック | ヒープ |
|---|---|---|
| 用途 | 関数実行 | 動的メモリ |
| 管理方法 | 自動管理 | プログラマ管理 |
| 速度 | 高速 | 比較的遅い |
| サイズ | 小さい | 大きい |
ヒープ領域は、主に mallocなどの関数で動的にメモリを確保するために使用されます。
スタックオーバーフローとは
スタック領域には サイズの上限があります。
そのため、スタックを使いすぎると
スタックオーバーフローが発生することがあります。
代表的な原因は次の通りです。
- 深い再帰呼び出し
- 大きすぎるローカル配列
例えば次のコードです。
void func() {
int buffer[100000];
}このように 大きな配列をローカル変数として確保すると
スタックを圧迫する可能性があります。
その場合は
- ヒープを使用する
- 配列サイズを見直す
などの対策が必要です。
メモリ構造の中でのスタック
C言語のプログラムでは、メモリは一般的に次のような構造になっています。
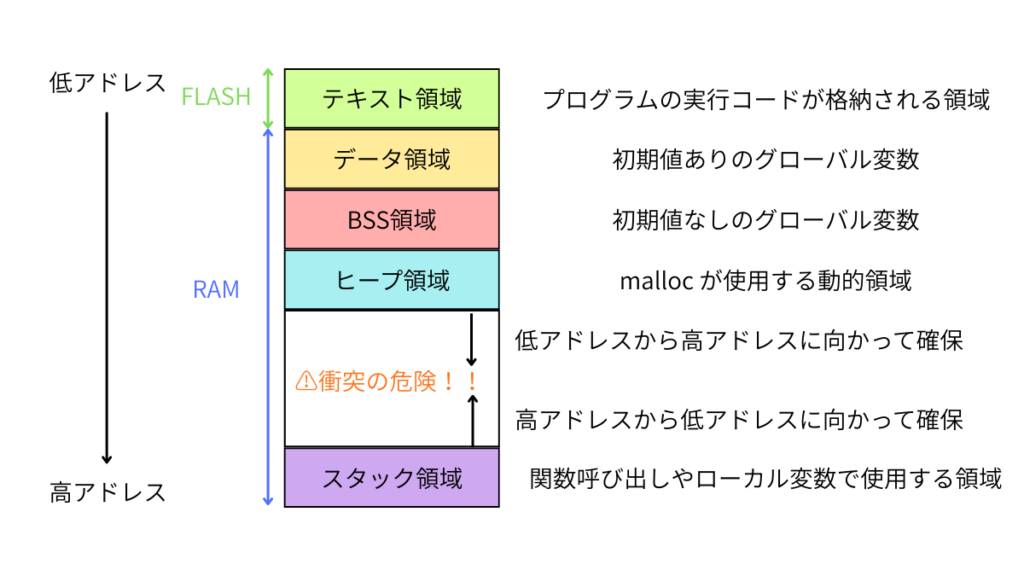
スタックは 高アドレス側から上方向に伸びることが多く、
ヒープは 低アドレス側から下方向に伸びる構造になっています。
まとめ
スタック領域は、関数の実行に必要な情報を保存する重要なメモリ領域です。
ポイントをまとめます。
- スタックは関数呼び出しで使用される
- ローカル変数や戻りアドレスが保存される
- LIFO構造を持つ
- メモリは自動管理される
- ヒープとは用途と管理方法が異なる
C言語のメモリ構造を理解する上で、
スタック領域とヒープ領域の違いは非常に重要なポイントです。
この記事が参考になった方へ
メモリ領域については他の記事でも解説しています。
技術に関するご相談・開発・自動化ツール作成・記事執筆などのご依頼も承っています。
小さなご相談からでもお気軽にご連絡ください。





コメント